Description of the method used¶
RALFit computes a solution 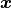 to the non-linear least-squares problem
to the non-linear least-squares problem
(1)¶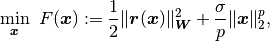
Here we describe the method used to solve (1). RALFit implements an iterative method that, at each iteration, calculates and returns a step  that reduces the model by an acceptable amount by solving (or approximating a solution to) a
subproblem, as detailed in Subproblem solves.
that reduces the model by an acceptable amount by solving (or approximating a solution to) a
subproblem, as detailed in Subproblem solves.
The algorithm is iterative.
At each point,  , the algorithm builds a model of the function at the next step,
, the algorithm builds a model of the function at the next step,  , which we refer to as
, which we refer to as  . We allow either a Gauss-Newton model, a (quasi-)Newton model, or a Newton-tensor model;
see The models for more details.
. We allow either a Gauss-Newton model, a (quasi-)Newton model, or a Newton-tensor model;
see The models for more details.
Once the model has been formed we find a candidate for the next step by solving a subitable subproblem. The quantity
(2)¶
is then calculated.
If this is sufficiently large we accept the step, and
![\iter[k+1]{\vx}](_images/math/24f0316cff03d9646922df41b93a270f707ffd9a.png) is set to
is set to
 ; if not, the parameter
; if not, the parameter
 is reduced and the resulting new trust-region sub-problem is solved.
If the step is very successful – in that
is reduced and the resulting new trust-region sub-problem is solved.
If the step is very successful – in that
 is close to one –
is increased. Details are explained in Accepting the step and updating the parameter.
is close to one –
is increased. Details are explained in Accepting the step and updating the parameter.
This process continues until either the residual,
 , or a measure of the gradient,
, or a measure of the gradient,
 ,
is sufficiently small.
,
is sufficiently small.
The models¶
A vital component of the algorithm is the choice of model employed.
There are four choices available, controlled by the parameter
model of nlls_options.
model = 1this implements the Gauss-Newton model. Here we replace
![\vr(\iter[k]{\vx} + \vs)](_images/math/31a6f07d3f59ac6a88a6093750477323858acdd6.png) by its first-order Taylor
approximation,
by its first-order Taylor
approximation,  . The model is
therefore given by
. The model is
therefore given by(3)¶

model = 2this implements the Newton model. Here, instead of approximating the residual,
 , we take as our model the
second-order Taylor approximation of the function,
, we take as our model the
second-order Taylor approximation of the function,
![F(\iter[k+1]{\vx}).](_images/math/7c8a644a71e4fe0a05ac42dcc453ef8c7d71163d.png) Namely, we use
Namely, we use(4)¶

where
 and
and
![\iter{\vH} = \sum_{i=1}^m\iter[i]{r}(\iter{\vx}) \vW \nabla^2 \iter[i]{r}(\iter{\vx}).](_images/math/e579b796dda436d9c22d1bdec11491f00373b562.png) Note that
Note that
 .
.If the second derivatives of
are not available (i.e.,
the option exact_second_derivativesis set tofalse, then the method approximates the matrix ; see Approximating the Hessian.
; see Approximating the Hessian.model = 3This implements a hybrid model. In practice the Gauss-Newton model tends to work well far away from the solution, whereas Newton performs better once we are near to the minimum (particularly if the residual is large at the solution). This option will try to switch between these two models, picking the model that is most appropriate for the step. In particular, we start using
 , and switch to
, and switch to  if
if
 for more than
for more than hybrid_switch_itsiterations in a row. If, in subsequent iterations, we fail to get a decrease in the function value, then the algorithm interprets this as being not sufficiently close to the solution, and thus switches back to using the Gauss-Newton model.The exact method used is described below:
![& \mathbf{if } \texttt{ use\_second\_derivatives} \qquad
\textit{ // previous step used Newton model} \\
& \qquad \mathbf{if } \|\iter[k+1]{\tg}\| > \|\iter[k]{\tg} \| \\
& \qquad \qquad \texttt{use\_second\_derivatives = false} \qquad
\textit{ // Switch back to Gauss-Newton} \\
& \qquad \qquad {\iter[temp]{\thess}} = \iter[k]{\thess}, \ \iter[k]{\thess} = 0
\qquad \textit{ // Copy Hessian back to temp array} \\
& \qquad \mathbf{end if } \\
& \mathbf{else} \\
& \qquad \mathbf{if } \|\iter[k+1]{\tg}\| / \texttt{normF}_{k+1} < \texttt{hybrid\_tol} \\
& \qquad \qquad \texttt{hybrid\_count = hybrid\_count + 1} \qquad
\textit{ // Update the no of successive failures} \\
& \qquad \qquad \textbf{if } \texttt{hybrid\_count = hybrid\_count\_switch\_its} \\
& \qquad \qquad \qquad \texttt{use\_second\_derivatives = true} \\
& \qquad \qquad \qquad \texttt{hybrid\_count = 0} \\
& \qquad \qquad \qquad \iter[temp]{\thess} = {\iter[k]{\thess}}
\textit{// Copy approximate Hessian back} \\
& \qquad \qquad \textbf{end if} \\
& \qquad \textbf{end if} \\
& \textbf{end if} \\](_images/math/6ef2c1c5fb1a9b1d40afc245ef18365e1b284daf.png)
model = 4this implements a Newton-tensor model. This uses a second order Taylor approximation to the residual, namely

where
 is the ith row of
is the ith row of  , and
, and
 is
is  . We use this to define our model
. We use this to define our model(5)¶

Approximating the Hessian¶
If the exact Hessian is not available, we approximate it using the method of Dennis, Gay, and Welsch [4]. The method used is given as follows:
![& \textbf{function} \ \iter[k+1]{\thess} = \mathtt{rank\_one\_update}(\td ,\iter[k]{\tg},\iter[k+1]{\tg}, \iter[k+1]{\tr},\iter[k]{\tJ},\iter[k]{\thess}) \\
& \ty = \iter[k]{\tg} - \iter[k+1]{\tg} \\
& \widehat{\ty} = {\iter[k]{\tJ}}^T \iter[k+1]{\tr} -
\iter[k+1]{\tg} \\
& \widehat{\iter[k]{\thess}} = \min\left(
1, \frac{|\td^T\widehat{\ty}|}{|\td^T\iter[k]{\thess}\td|}\right)
\iter[k]{\thess} \\
& \iter[k+1]{\thess} =
\widehat{\iter[k]{\thess}} + \left(({\iter[k+1]{\widehat{\ty}}} -
\iter[k]{\thess}\td )^T\td\right)/\ty^T\td](_images/math/e3a0e3b356e8f4a67f195b1b4d2c99a0aa52a2fc.png)
It is sometimes the case that this approximation becomes corrupted, and
the algorithm may not recover from this. To guard against this,
if model = 3 in nlls_options and we are using this approximation to
the Hessian in our (quasi-Newton) model, we test against the Gauss-Newton
model if the first step is unsuccessful. If the Gauss-Newton step would have been
successful, we discard the approximate Hessian information, and recompute the
step using Gauss-Newton.
In the case where model=3, the approximation to the Hessian is updated at each step
whether or not it is needed for the current calcuation.
Subproblem solves¶
The main algorithm calls a number
of subroutines. The most vital is the subroutine calculate_step, which
finds a step that minimizes the model chosen, subject to a globalization
strategy. The algorithm supports the use of two such strategies: using a
trust-region, and regularization. If Gauss-Newton, (quasi-)Newton, or a
hybrid method is used (model = 1,2,3 in nlls_options),
then the model function is
quadratic, and the methods available to solve the subproblem are
described in The trust region method and Regularization.
If the Newton-Tensor model is selected (model = 4 in nlls_options), then this model
is not quadratic, and the methods available are described in
Newton-Tensor subproblem.
Note that, when calculating the step, if the initial regularization
parameter  in (1) is non-zero,
then we must modify
in (1) is non-zero,
then we must modify ![{\iter[k]{\tJ}}^T\iter[k]{\tJ}](_images/math/e6f56693288dc85daf3e156bc7711bbab6406764.png) to take into
account the Jacobian of the modified least squares problem being solved.
Practically, this amounts to making the change
to take into
account the Jacobian of the modified least squares problem being solved.
Practically, this amounts to making the change
![{\iter[k]{\tJ}}^T\iter[k]{\tJ} = {\iter[k]{\tJ}}^T\iter[k]{\tJ} +
\begin{cases}
\sigma I & \text{if }p = 2\\
\frac{\sigma p}{2} \|\iter[k]{\vx}\|^{p-4}\iter[k]{\vx}{\iter[k]{\vx}}^T & \text{otherwise}
\end{cases}.](_images/math/9ac5f8dff206acd020a1438425c20888eba27e82.png)
The trust region method¶
If model = 1, 2, or 3, and type_of_method=1, then we solve the subproblem
(6)¶
and we take as our next step the minimum of the model within some radius of the current point. The method used to solve this is dependent on the control parameter optionsnlls_method. The algorithms called for each of the options are listed below:
nlls_method = 1approximates the solution to (6) by using Powell’s dogleg method. This takes as the step a linear combination of the Gauss-Newton step and the steepest descent step, and the method used is described here:

nlls_method = 2- solves the trust region subproblem using the trust region solver of Adachi, Iwata, Nakatsukasa, and Takeda. This reformulates the problem (6) as a generalized eigenvalue problem, and solves that. See [1] for more details.
nlls_method = 3- this solves (6) using a variant of the More-Sorensen method. In particular, we implement Algorithm 7.3.6 in Trust Region Methods by Conn, Gould and Toint [2].
nlls_method = 4this solves (6) by first converting the problem into the form

where
 is a diagonal matrix. We do this by performing an
eigen-decomposition of the Hessian in the model. Then, we call the
Galahad routine DTRS; see the Galahad [3] documentation for further
details.
is a diagonal matrix. We do this by performing an
eigen-decomposition of the Hessian in the model. Then, we call the
Galahad routine DTRS; see the Galahad [3] documentation for further
details.
Regularization¶
If model = 1, 2, or 3, and type_of_method=2, then the next step is taken to be the
minimum of the model with a regularization term added:
(7)¶
At present, only one method of solving this subproblem is supported:

Newton-Tensor subproblem¶
If model=4, then the non-quadratic Newton-Tensor model is used.
As such, none of the established subproblem solvers described in
The trust region method or Regularization can be used.
If we use regularization (with  ), then the subproblem we need
to solve is of the form
), then the subproblem we need
to solve is of the form
(8)¶
Note that (8) is a
sum-of-squares, and as such can be solved by calling nlls_solve()
recursively. We support two options:
inner_method = 1if this option is selected, then
nlls_solve()is called to solve (5) directly. The current regularization parameter of the ‘outer’ method is used as a base regularization in the ‘inner’ method, so that the (quadratic) subproblem being solved in the ‘inner’ call is of the form
where
 is a quadratic model of
(5), is the (fixed)
regularization parameter of the outer iteration, and
is a quadratic model of
(5), is the (fixed)
regularization parameter of the outer iteration, and  the regularization parameter of the inner iteration, which is free to be
updated as required by the method.
the regularization parameter of the inner iteration, which is free to be
updated as required by the method.inner_method = 2in this case we use
nlls_solve()to solve the regularized model (8) directly. The number of parameters for this subproblem is .
Specifically, we have a problem of the form
.
Specifically, we have a problem of the form
This subproblem can then be solved using any of the methods described in The trust region method or Regularization.
inner_method = 3
In this case,nlls_solve()is called recursively with the inbuilt feature of solving a regularized problem, as described in Incorporating the regularization term
Accepting the step and updating the parameter¶
Once a step has been suggested, we must decide whether or not to accept the step, and whether the trust region radius or regularization parameter, as appropriate, should grow, shrink, or remain the same.
These decisions are made with reference to the parameter, (2),
which measures the ratio of the actual reduction in the model to the
predicted reduction in the model. If this is larger than
eta_successful in nlls_options, then the step
is accepted.
The value of then needs to be updated, if appropriate.
The package supports two options:
tr_update_strategy = 1a step-function is used to decide whether or not to increase or decrease
,
as described here:
tr_update_strategy = 2a continuous function is used to make the decision [5], as described below. On the first call, the parameter
 is set to
is set to  .
.
Incorporating the regularization term¶
If regularization = 0, then no regularization is added.
A non-zero regularization term can be used in (1) by setting regularization to be non-zero.
This is done by transforming the problem internally into a new non-linear least-squares problem.
The formulation used will depend on the value of regularization in nlls_options, as described below.
regularization = 1This is only supported if
 .
We solve a least squares problem with
.
We solve a least squares problem with
 additional degrees of freedom. The new function,
additional degrees of freedom. The new function,
 , is defined as
, is defined as![\widehat{\vr}_i(\vx) = \begin{cases}
\vr_i(\vx) & \text{for } i = 1,\dots, m \\
\sqrt{\sigma}[\vx]_j & \text{for } i = m+j, \ j = 1,\dots,n
\end{cases}](_images/math/5715268bbe48f593ad1199d88a7e413a1091b765.png)
where
![[\vx]_j](_images/math/e7d86b1515a1cd5f55b6748f675b7fbac30c8d16.png) denotes the
denotes the  th component of .
th component of .This problem is now in the format of a standard non-linear least-squares problem. In addition to the function values, the we also need a Jacobian and some more information about the Hessian. For our modified function, the Jacobian is

and the other function that needs to be supplied is given by

We solve these problems implicitly by modifing the code so that the user does not need do any additional work. We can simply note that


and that

We also need to update the value of the model. Since the Hessian vanishes, we only need to be concerned with the Gauss-Newton model. We have that

regularization=2
We solve a non-linear least-squares problem with one additional degree of freedom.
Since the term
is non-negative, we can write
thereby defining a new non-linear least squares problem involving the function
such that
The Jacobian for this new function is given by
and we get that
As for the case where
regularization=1, we simply need to update quantities in our non-linear least squares code to solve this problem, and the changes needed in this case are
We also need to update the model. Here we must consider the Gauss-Newton and Newton models separately.
If we use a Newton model then










Bound constraints¶
RALFit can solve the bound constrained problem to find that solves the non-linear least-squares problem

RALFit handles the bound constraints by projecting candidate points into the feasible set. The implemented framework is an adaptation of Algorithm 3.12 described by Kanzow, Yamashita, and Fukushima [6], where the Levenberg-Marquardt step is replaced by a trust region one. The framework consists of three major steps. It first attempts a projected trust region step and, if unsuccessful, it attempts a Wolfe-type linesearch step along the projected trust region step direction; otherwise, it defaults to a projected gradient step with the Armijo-type linesearch. Specifically:
Trust Region Step The trust region loop needs to be interrupted if the proposed steps
 lead to points outside of the feasible set,
i.e., they are orthogonal with respect to the active bounds.
This is monitored by the ratio
lead to points outside of the feasible set,
i.e., they are orthogonal with respect to the active bounds.
This is monitored by the ratio  ,
where
,
where  is the Euclidean projection operator over the feasible set.
is the Euclidean projection operator over the feasible set.
 provides a convenient way to asses how severe the projection is,
if
provides a convenient way to asses how severe the projection is,
if  , then the step is indeed orthogonal
to the active space and does not provide a suitable search direction, so
the loop is terminated.
On the contrary, if
, then the step is indeed orthogonal
to the active space and does not provide a suitable search direction, so
the loop is terminated.
On the contrary, if  then has components
that are not orthogonal to the active set that can be explored.
The trust region step is taken when it is deemed that it makes enough progress
in decreasing the error.
then has components
that are not orthogonal to the active set that can be explored.
The trust region step is taken when it is deemed that it makes enough progress
in decreasing the error.Linesearch step This step is attempted when the trust region step is unsuccessful but
 is a descent direction,
and a viable search direction in the sense that
is a descent direction,
and a viable search direction in the sense that(9)¶

with
the trust region step,  and
and  .
RALFit performs a weak Wolfe-type linesearch along this direction to find the next point.
During the linesearch the intermediary candidates are projected into the feasible set
and kept feasible.
.
RALFit performs a weak Wolfe-type linesearch along this direction to find the next point.
During the linesearch the intermediary candidates are projected into the feasible set
and kept feasible.Projected gradient step The projected gradient step is only taken if both the trust region step and the linesearch step where unsuccessful. It consists of an Armijo-type linesearch along the projected gradient direction,
 .
.
| [1] | Adachi, Satoru and Iwata, Satoru and Nakatsukasa, Yuji and Takeda, Akiko (2015). Solving the trust region subproblem by a generalized eigenvalue problem. Technical report, Mathematical Engineering, The University of Tokyo. |
| [2] | Conn, A. R., Gould, N. I., & Toint, P. L. (2000). Trust region methods. SIAM. |
| [3] | (1, 2) Gould, N. I., Orban, D., & Toint, P. L. (2003). GALAHAD, a library of thread-safe Fortran 90 packages for large-scale nonlinear optimization. ACM Transactions on Mathematical Software (TOMS), 29(4), 353-372. |
| [4] | Nocedal, J., & Wright, S. (2006). Numerical optimization. Springer Science & Business Media. |
| [5] | Nielsen, Hans Bruun (1999). Damping parameter in Marquadt’s Method. Technical report TR IMM-REP-1999-05, Department of Mathematical Modelling, Technical University of Denmark (http://www2.imm.dtu.dk/documents/ftp/tr99/tr05_99.pdf) |
| [6] | Kanzow, C., Yamashita, N. and Fukushima, M (2004). Levenberg-Marquardt methods with strong local convergence properties for solving nonlinear equations with convex constraints. Journal of Computational and Applied Mathematic 172(2), 375-397. |